演示Demo
知识宝库 - 支付
查看隐藏内容,需支付
3金币 !
音频切片+音频标注+模型训练首先,我们需要对训练声音素材进行提纯处理,去除掉背景音和杂音。这里推荐使用UVR工具进行声音提纯。
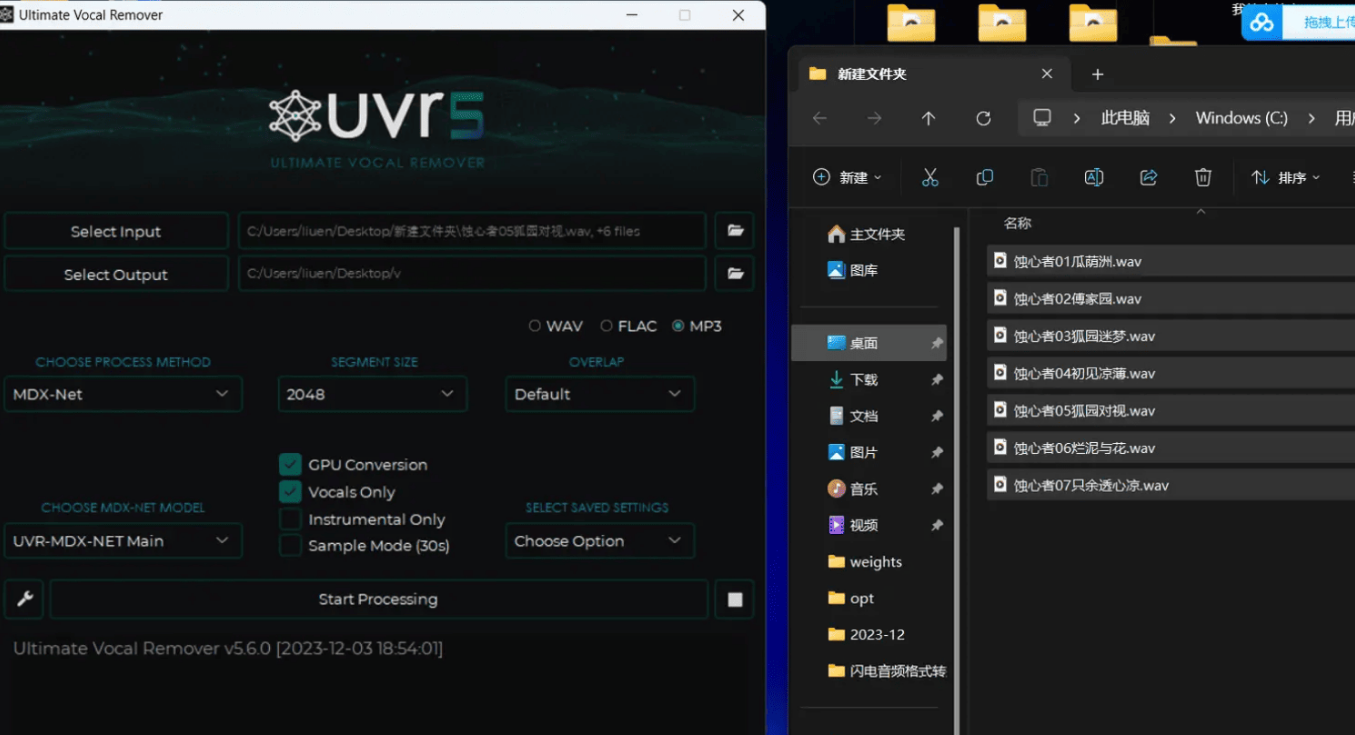
二、对声音素材进行切片
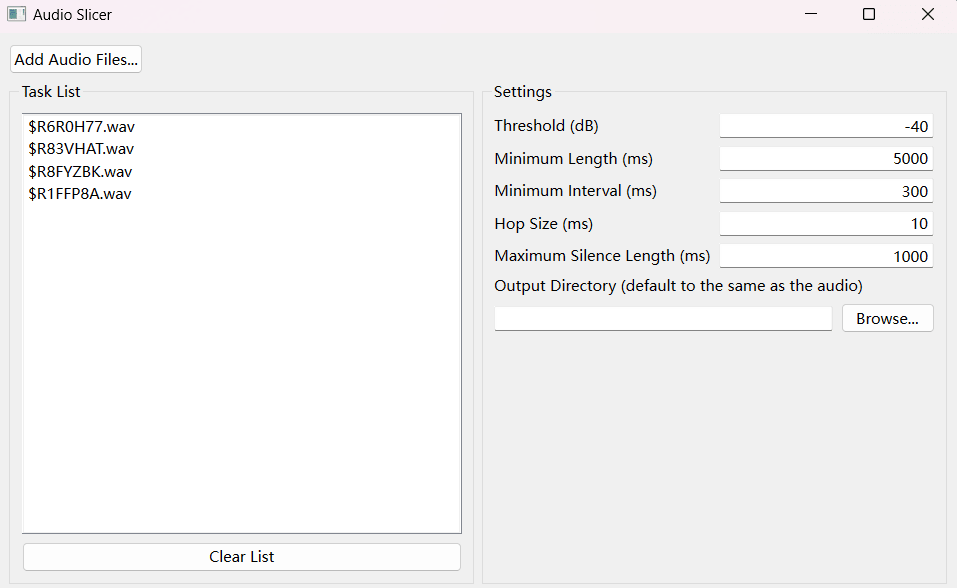
三、对分段音频 进行 文本标注切片好的音频经过手动筛选过短的音频 放入 raw_audio
点击 0.带标点符号的标注
标注完成
打开 bert vist2 整合包启动 webui
创建 文件夹
启动 webui创建训练的模型自己创建目录 将切好片的声音文件 放入 custom_character_voice将标注好的文本放入 filelists
文本预处理
生成bert 文件
生成 emo文件
写入 训练参数 批大小 根据显卡设置 我这里设置16
训练中